
1、CrossCheck是什么?
CrossRef首创并与iParadigms公司共同开发出一个全新的,用于帮助学术出版者验证出版文档原创性的新工具CrossCheck,CrossCheck的功能由两部分组成:一个基于全球学术出版物所组成的庞大数据库(CrossRef)和一个基于网页的比对工具(iThenticate)。这个基于网页的工具通过程序算法用于比对鉴别相似内容,生成对比报告,并通过分析去判断是否存有学术剽窃行为。
2、CrossCheck检测论文会收录吗?
由CrossCheck中文网站检测的论文不会收录到数据库,属于无痕检测,不会影响之后投稿时杂志社的检测结果,投稿前预查重的首选检测工具.
3、检测时需要把Reference加上吗?
请确保检测的内容跟投稿到杂志社的一样,假如投稿到杂志社的论文是包括Reference部分的请在中文网站检测时也保留Reference,因为有无Reference的内容对查重结果影响可能会比较大,同学们请注意,删除Reference检测和排除Reference报告是不同的,请不要搞混,如果有Reference部分我们一般会提供2份PDF格式的检测报告,一份是包括Reference重复结果的报告,一份是排除Reference重复结果的报告,方便同学们查阅,整体把握论文相似性!
4、检测时需要提供哪种格式的文档?word格式还是PDF格式的?
这两种格式系统都是可以检测的,我们建议检测的格式跟投稿时一样,如果投稿是word格式则检测word格式,是PDF格式则检测PDF格式,另外同一篇论文,不同的格式系统计算的字数是不相同的,一般PDF格式文字的字数要比word格式多,具体字数以提交时系统统计的为准。
5、CrossCheck的收费标准是?
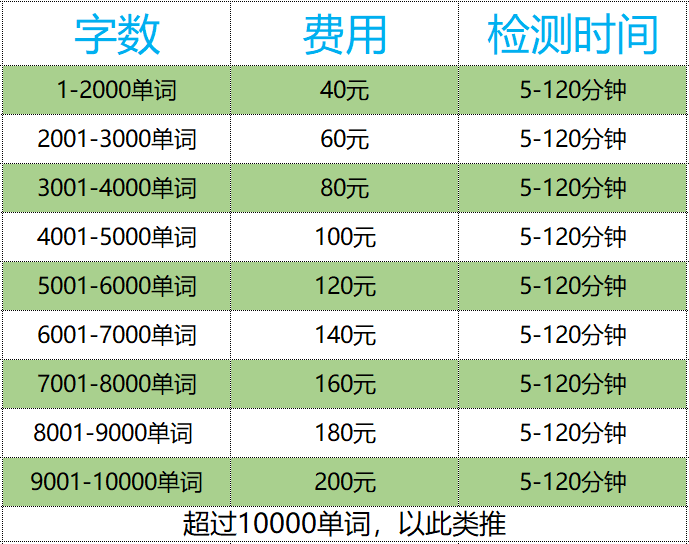
6、同一篇论文是否可以重复检测?
系统是无痕检测的,不会限制文档的检测次数,也不会影响投稿的检测结果,每一篇文档都可以多次检测,但是付一次费用只可以检测一次哦,如果修改后(或者未修改)再次进行检测,需要再次根据文档的字数付费的。
7、CrossCheck检测报告如何解读?
检测完成后会提供PDF格式的检测报告:
1)、报告中的内容会有各种颜色标示,标示了颜色的说明是检测到重复的,不同的颜色只是用于区分重复源不同;
2)、颜色上方的数字是序号,跟报告后面的重复来源对应,方便同学们查阅,序号越小说明与此重复源的相同内容越多;
3)、SIMILARITY INDEX是指检测的总重复率,杂志社一般是看这个指标(也有部分杂志对单重复源有要求,具体请咨询对应期刊),总重复率是由下面的Crossref、Internet、Publications等数据库的重复通过程序算法权加得到(由于每篇论文的内容不同,报告上只会列出检测到与该数据库有重复的数据库来源,具体以实际得到的报告为准);
4)、报告的重复源链接一般是无法打开的,因为里面的数据库基本上是不对外开放的,重复内容查看报告上的即可;
5)、默认提交的内容系统都会比对,比如作者名称、地址、联系电话等,系统不会识别并排除这部分的重复,投稿到杂志社的检测结果也是一样的;
6)、系统是语义检测的,并无固定的多少个词连在一起才算重复,具体的结果以实际上报告的标示为准.
8、CrossCheck的比对数据库有哪些?
CrossCheck检测系统的数据库包括但不限于:来自115,000个科学、技术和医学期刊的69000000+学术文章,书籍,会议论文集,来自于期刊,杂志,学报,百科全书和文摘的135000000+发表的作品和70000000000+的在线和存档的网页等。
9、CrossCheck中文网站检测的结果跟杂志社的有差别吗?
只要杂志社是使用CrossCheck检测来稿,相同的内容在中文网站检测的结果就和杂志社是一致的,因为都是使用相同的检测系统,可作为同学们投稿预查重的首选系统.
10、你们网站的查重结果与投稿期刊查的结果一致吗?
同时满足以下3个条件,结果是与期刊查的一致的:
1)、期刊使用的查重系统为CrossCheck,结果为系统默认的结果(不人为设置限制参数);
2)、查重的版本为投稿的版本,就是说检测的内容、字数要一样(比如在我们网站查删除了参考文献等内容,而投稿时包含参考文献等,此为检测内容不一样);
3)、查重的时间间隔相差不宜过大,因为数据库是实时更新的,约定为我们网站查重和期刊查重的间隔不超过15天;
满足了以上条件如果与期刊查重的SIMILARITY INDEX结果不一致,SIMILARITY INDEX相差超过5%,可以提供我们网站和期刊的查重报告给客服确认,确认无问题后可以全额退还当次的检测费用。
11、重复率过高,有什么方法修改可以降低重复率?
1)、替换句子中的关键字、关键字用同义替换。对于一般论文作用明显,但是非常专业性的论文有许多专业术语,无法替换,效果不明显。
2)、改变带颜色部分的句式,打乱结构。这种方法适用性很强,改变句式,同时替换关键词语,效果可能比较好。
3)、图片转换法。图片中的文字,检测系统是无法识别,尽量将重复的表格转换成图片。但是,论文的总字数可能降低。
4)、适当删除带颜色的句子。过多的删除重复的句子,影响论文的整体结构以及质量。
12、重复率控制在多少以内会比较安全?
目前,没有一个很直观准确的标准来界定什么是重复、抄袭,任何检测报告也是仅供参考。如果不清楚杂志社的要求,根据我们的经验,争取把SIMILARITY INDEX的结果控制在10%以下会相对保险些,当然是越低越好,这样可以避免杂志社以重复率过高而拒稿!
13、为什么一次带reference检测、一次不带reference检测,正文同一部分检测的不一样?
因为系统是语义检测,会根据上下文来匹配比对,删掉Reference list会影响系统检测的敏感度,进而影响到正文内容的检测,我们建议检测的内容跟投稿到期刊杂志社的完全一样,这样才能保证跟编辑部检测结果的一致性。
14、我有复制或引用了别人的内容,为什么检测重复率很低或者是0%,甚至没有标明重复?
任何一个系统都不能包罗万象,收录所有的文字,如果你复制的文字不在系统的数据库里,就会出现检测结果很低或者是0%的现象。如检测结果为0,说明在iThenticate的数据库中没有检测到重复的内容,并非不准,相同的内容在杂志社的检测结果也是相同的。引用reference了没有被查到,说明数据库没有收录到此部分内容,因为这个系统也是购买国外各大出版商的权限,有的出版商可能不在购买之列,所以存在引用了不被查到的可能。
同理,有人讲,明明我是引用书本里的,为什么显示跟别人的论文或者作业什么抄袭?
根本原因在于数据库没有收录书本,但是前面有人引用了该书本的内容,那么再引用该书本就会造成跟前人的作业或者发表的论文显示重复。针对这样,建议还是正确引用,正确标注。
15、为什么一句话几个单词也标示重复,而且还是相隔开的?
系统是语义检测的,只要系统判断到跟数据库的内容相似,都会标示出来,并且有可能分布在前后几句里,不一定是连续的。
16、CrossCheck支持哪些类型的文档?
系统可支持:MS Word, Word XML, WordPerfect, PostScript, PowerPoint (.PPT, .PPTX), PDF, HTML, RTF, HWP, OpenOffice (ODT) and plain text格式的文档。
17、我可以删除图表、参考文献等内容再提交查重吗?
查重内容是完全可以自己决定的,原则上你想查哪部分内容你就提交哪部分内容即可,但是我们建议是保持文章的完整性,查重的内容需要跟投稿的版本完全一样,预查重的目的是为了规避投稿时期刊不会因为重复率高而拒稿,假如你预查重的内容跟投稿的内容不一样,结果也是不一样的,这样预查重的目的就失去了意义,因为查重系统的算法是很复杂的,上下文间会相互影响。
18、如何区分包括参考文献和排除参考文献的结果?
包括参考文献是指论文中的参考文献也按正文的标准进行检测标示,排除参考文献是指论文中的参考文献排除在检测之列,不计算到重复率上,可能与一部分同学理解的删除参考文献不同,除了报告文档标题标示外,最主要是区分是看报告最后一页页脚的标示:EXCLUDE BIBLIOGRAPHY 后面的OFF 和 ON, OFF表示包括参考文献,ON表示的是排除参考文献。
19、之前不重复的内容,为什么第二次查重变成重复的了?
系统的算法如是,会根据文章的上下文判断,如果文章进行了修改,即使之前不重复的内容,有可能在新的语义判断范围内是属于重复的,当然也会有之前重复的内容,在修改了文章其它内容时检测又被列为不重复,原理是相同的,因此,不需要比较修改前后几次的报告,只需要确保最新修改的重复率达到投稿期刊的要求即可放心投稿,前提是查重的文章是投稿版本。
20、已发表的文章能查重吗?
可以的,原则上只要是由文字组成的文章都可以查重,已发表的文章查重默认的重复率会比较高,因为有可能这篇文章已经收录到系统的数据库了,就是会自重复,一般来说发表的年份越久,检测到的与之重复的文献就越多,已发表文章的查重需要联系客服检测,我们可以协助剔除自重复的内容以及部分在发表年份后比较高重复的来源,这里说的剔除是指剔除重复后再生成报告,并不是指从系统删除这个重复源,如果期刊或者单位后面再查重,仍然是默认的重复率。